psychophys#
- class perceptivo.types.psychophys.Sample(sound: perceptivo.types.sound.Sound, dilation: typing.Optional[perceptivo.types.pupil.Dilation] = None, timestamp: datetime.datetime = <factory>, response: dataclasses.InitVar[bool] = <property object>)#
Bases:
objectA single sample of a psychophysical response to a sound
- Variables
~Sample.dilation (
types.pupil.Dilation) – Pupil object storing dilation for a given sample~Sample.sound (
types.sound.Sound) – Sound presented to elicit Pupil response~Sample.timestamp (
datetime.datetime) – Timestamp at which the response was elicited
- Properties:
response (bool): Sub/Subtrathreshold response from
Pupil.response
- dilation: Optional[perceptivo.types.pupil.Dilation] = None#
- timestamp: datetime.datetime#
- class perceptivo.types.psychophys.Samples(samples: Optional[List[perceptivo.types.psychophys.Sample]] = None, dilations: Optional[List[perceptivo.types.pupil.Dilation]] = None, frequencies: Optional[List[float]] = None, amplitudes: Optional[List[float]] = None, responses: Optional[List[bool]] = None)#
Bases:
objectMultiple Samples!
Convenience class to init samples from numpy arrays and convert to pandas dataframe
- samples: List[perceptivo.types.psychophys.Sample]#
- append(sample: perceptivo.types.psychophys.Sample)#
Add a sample to the collection
- Parameters
sample (
Sample) – A New Sample!
- to_df() pandas.core.frame.DataFrame#
Make a dataframe with sound parameterization flattened out
- plot(show=True)#
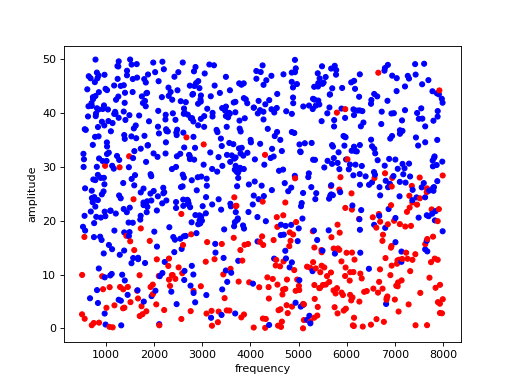
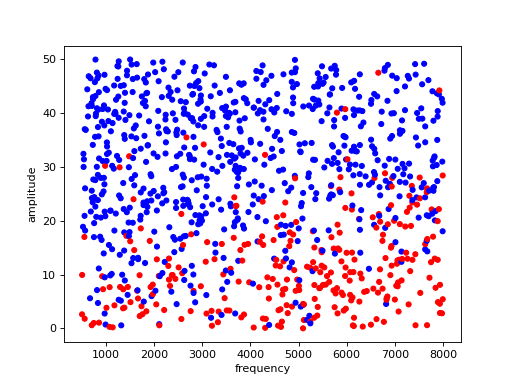
Plot a collection of samples as points, with blue meaning the sample was audible and red meaning inaudible
Examples
from perceptivo.psychophys.oracle import generate_samples samples = generate_samples(n_samples=1000, scale=10) samples.plot()
(Source code, png, hires.png, pdf)
- Parameters
show (bool) – If
True(default), call plt.show()
{kind=link}
{kind=link}
- class perceptivo.types.psychophys.Threshold(frequency: float, threshold: float, confidence: float = 0)#
Bases:
objectThe audible threshold for a particular frequency
- Parameters
frequency (float) – Frequency of threshold in Hz
threshold (float) – Audible threshold in dbSPL
confidence (float) – Confidence of threshold, units vary depending on estimation type
- class perceptivo.types.psychophys.Audiogram(thresholds: List[perceptivo.types.psychophys.Threshold])#
Bases:
objectA collection of :class:`.Threshold`s that represent a patient’s audiogram.
Thresholds can be accessed like a dictionary, using frequencies as keys, eg:
>>> agram = Audiogram([Threshold(1000, 10), Threshold(2000, 20)]) >>> agram[1000] Threshold(frequency=1000, threshold=10, confidence=0) >>> agram[3000] = Threshold(3000, 30) >>> agram[3000] Threshold(frequency=1000, threshold=10, confidence=0)
- thresholds: List[perceptivo.types.psychophys.Threshold]#
- property frequencies: List[float]#
List of frequencies in
thresholds
- class perceptivo.types.psychophys.Kernel(*, length_scale: Tuple[float, float] = (100.0, 200.0), length_scale_bounds: Tuple[float, float] = (1, 100000.0))#
Bases:
pydantic.main.BaseModelDefault kernel to use with
psychophys.model.Gaussian_ProcessUses a kernel with a short length scale for frequency, but a longer length scale for amplitude, which should be smoother/monotonic where frequency can have an unpredictable shape
Create a new model by parsing and validating input data from keyword arguments.
Raises ValidationError if the input data cannot be parsed to form a valid model.
- property kernel: sklearn.gaussian_process.kernels.RBF#
- class perceptivo.types.psychophys.Psychoacoustic_Model(model_type: typing.Literal['Gaussian_Process'] = 'Gaussian_Process', args: typing.Optional[list] = <factory>, kwargs: typing.Optional[typing.Dict[str, perceptivo.types.psychophys.Kernel]] = <factory>)#
Bases:
objectParameterization of a psychoacoustic model to use to estimate audiograms and control the presentation of stimuli
- model_type: Literal['Gaussian_Process'] = 'Gaussian_Process'#
- kwargs: Optional[Dict[str, perceptivo.types.psychophys.Kernel]]#