models#
- perceptivo.psychophys.model.f_to_bark(frequency: float) float#
Convert frequency to Bark using [WSG91]
- Parameters
frequency (float) – Frequency to convert
- Returns
(float) Bark
- perceptivo.psychophys.model.bark_to_f(bark: float) float#
Convert bark to frequency using inverted [WSG91]
- Parameters
bark (float) – bark to convert
- Returns
(float) frequency
- class perceptivo.psychophys.model.Audiogram_Model(freq_range: Tuple[float, float] = (125, 8500), amplitude_range: Tuple[float, float] = (5, 60), exam_params: Optional[perceptivo.types.exam.Exam_Params] = None, *args, **kwargs)#
Bases:
perceptivo.root.Perceptivo_ObjectMetaclass for Audiogram models and estimators.
These classes are used to estimate the audiogram, as well as control the order of the presentation of probe sounds.
Note
This class may be split into an experimental runner class and an audiogram model, but since the choice of the next stimulus should ideally be based on the current audiogram model, they are built together for now.
- Parameters
freq_range (tuple) – Tuple of two floats indicating min/max frequency (default: (125, 8500))
amplitude_range (tuple) – Tuple of two floats indicating min/max amplitude in dbSPL (default: (5,60))
- Variables
audiogram (
types.psychophys.Audiogram) – Audiogram of modelsamples (
types.psychophys.Samples) – Individual samples of frequency/amplitude and whether a sound was detected.
- abstract update(sample: perceptivo.types.psychophys.Sample)#
Update the model with a new :class:`~.types.psychophys.Sample
- abstract next() perceptivo.types.sound.Sound#
Generate parameters for the next
Soundto be presentedNext should generate samples that respect the frequencies and amplitudes set in
exam_params, if present. As well asallow_repeats
- class perceptivo.psychophys.model.Gaussian_Process(kernel: Optional[Union[sklearn.gaussian_process.kernels.Kernel, perceptivo.types.psychophys.Kernel]] = None, *args, **kwargs)#
Bases:
perceptivo.psychophys.model.Audiogram_ModelGaussian process model based on [CdeVries16]
Model: * Bayesian Process Classifier, predicting binary audibility as a function of frequency and amplitude * Kernel: * Covariance Function: Squared Exponent (RBF)
Process: * Convert sampled frequency to bark with
f_to_bark()* Update model * Generate next stimulus * Convert back to freqExamples
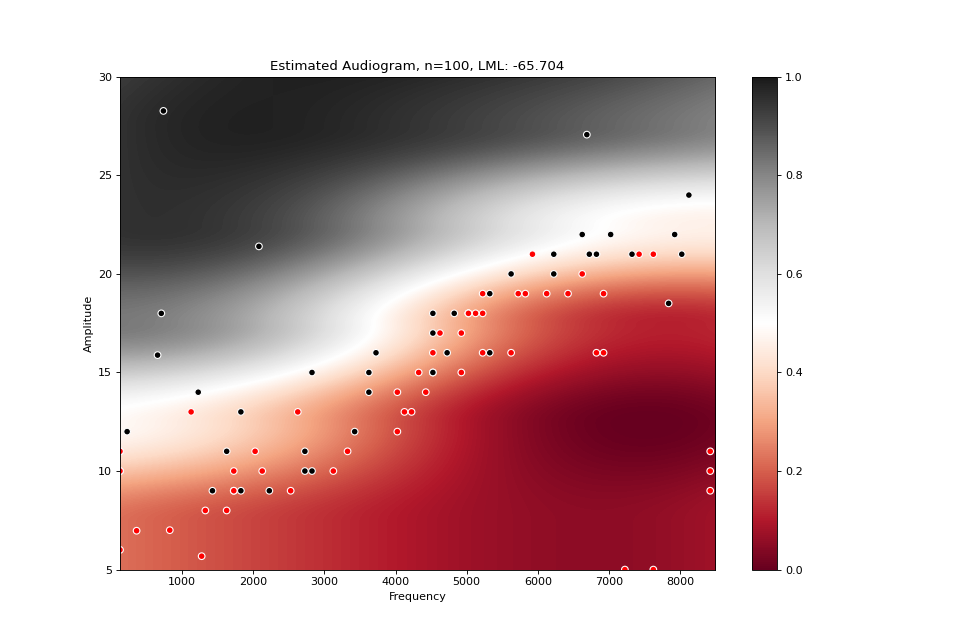
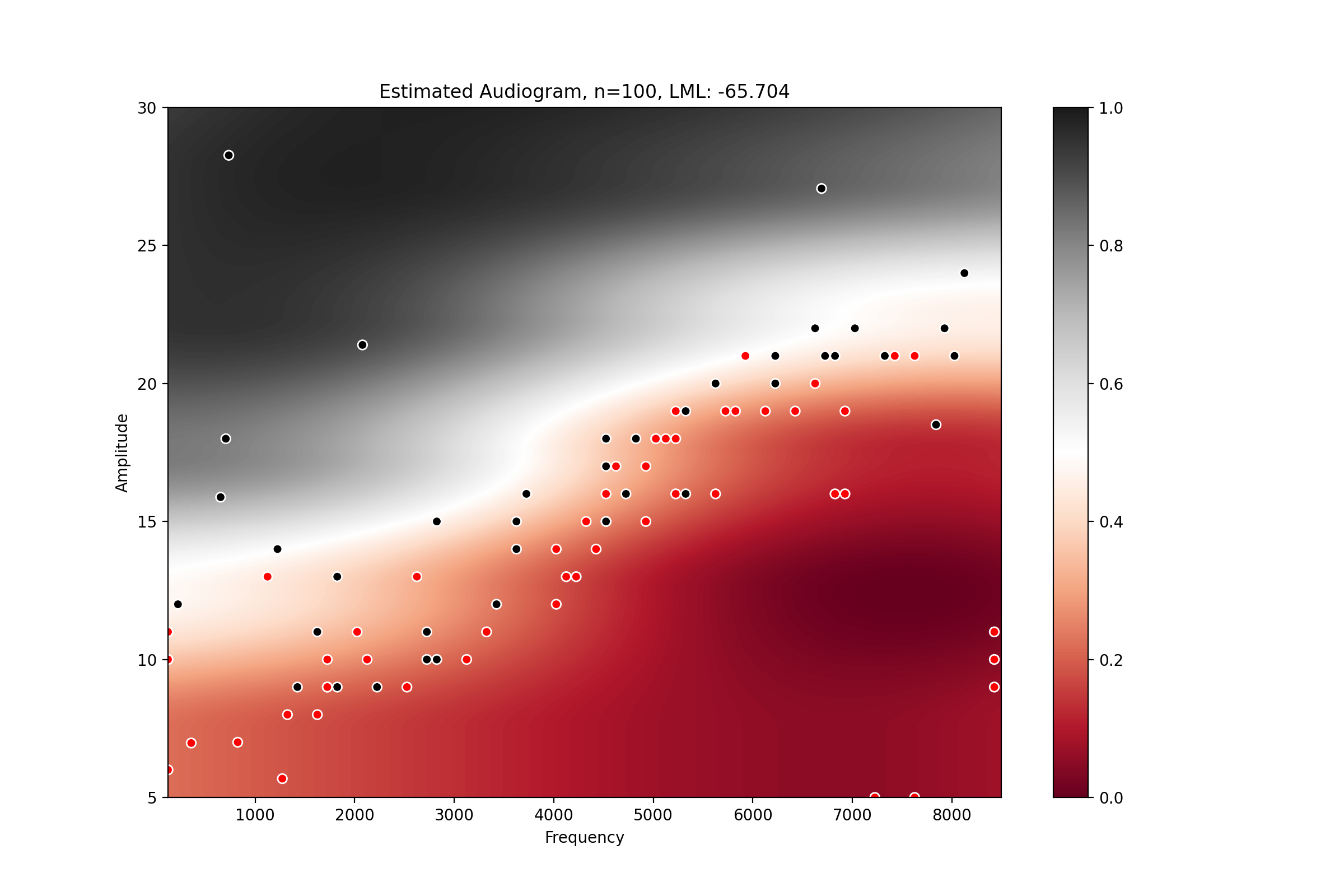
from perceptivo.psychophys.oracle import reference_audiogram from perceptivo.psychophys.model import Gaussian_Process from perceptivo.types.psychophys import Sample oracle = reference_audiogram(scale=3) model = Gaussian_Process(amplitude_range=(5,35)) for i in range(100): sound = model.next() sample = Sample(response=oracle(sound), sound=sound) model.update(sample) model.plot()
(Source code, png, hires.png, pdf)
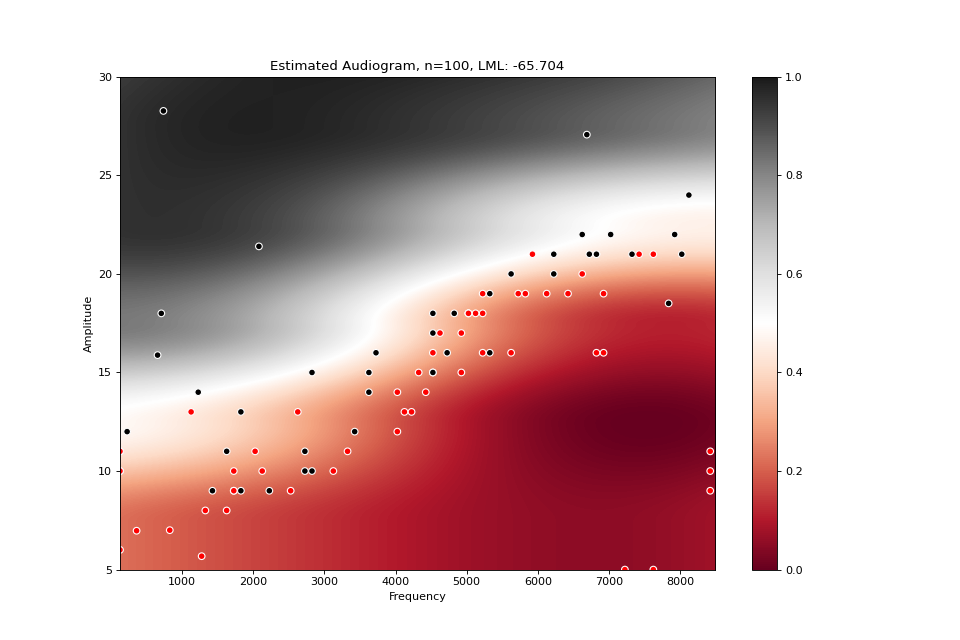
References
- property kernel: sklearn.gaussian_process.kernels.Kernel#
Kernel used in the gaussian process model. If
Noneis given on init, use thetypes.psychophys.Kernel- Returns
sklearn.gaussian_process.kernels.Kernel
- property samples: perceptivo.types.psychophys.Samples#
Stored samples from updates
- Returns
- update(sample: perceptivo.types.psychophys.Sample)#
Update the model with a new sample!
- Parameters
sample ()
- next() perceptivo.types.sound.Sound#
Generate parameters for the next sound to present
- Returns
{kind=link}
{kind=link}